

 The recent Amazon Web Services outage that took out huge swaths of the Internet a couple of weeks ago has been an eye opener for companies who rely heavily on the cloud. If you ever hope to avoid a similar multi-hour downtime in the future, it would help to pay attention to the crucial lessons we’ve learned from that incident.
The recent Amazon Web Services outage that took out huge swaths of the Internet a couple of weeks ago has been an eye opener for companies who rely heavily on the cloud. If you ever hope to avoid a similar multi-hour downtime in the future, it would help to pay attention to the crucial lessons we’ve learned from that incident.
That outage, which impacted several popular sites, including Adobe, Coursera, Imgur, Mailchimp, Medium, Quora, Slack, and Trello, to mention a few, was primarily caused by human error.
Members of the S3 (Simple Storage Service) team were debugging an issue that was affecting the S3 billing system. Unfortunately, one of the members accidentally placed an incorrect entry in one of the commands supposed to remove a small number of servers on one of the S3 subsystems. As a result, a much larger number of servers were taken out. This led to a domino effect.

An official explanation of the outage can be found here, so we won’t go into the details anymore. What we’re here to discuss are the lessons we can draw from that outage. These lessons apply to any organization who has started using the cloud, whether you’re a government agency, a large manufacturer, or a small private business.
Don’t put all your eggs in one basket
Even in this highly sophisticated age of cloud computing, the ancient adage of not putting your eggs in one basket apparently still holds. The big difference is that, in today’s IT, those “eggs” can be cloned before being placed in separate baskets. We call it redundancy.
In simple terms, that means creating replicas of your applications, servers, or systems, and deploying them separately. That way, if the active copy fails, the other one can take its place (a.k.a. active-passive configuration). Alternatively, you can also make both copies run simultaneously and share workload in order to prevent one system from getting overloaded (a.k.a. Active-active configuration).
In AWS or any cloud infrastructure, the simplest way to achieve redundancy is by deploying at least two instances of your applications. This entails installing those applications in separate virtual machines and running those VMs separately.
The purpose of redundancy is to eliminate a single point of failure. If one system fails, processes can still be redirected to the other system(s) while the crippled system is revived. Of course, it’s possible for both systems to be crippled.
This can happen if the two systems are deployed in the same geographical location. For example, if the two systems are running in the same data center and that datacenter is inundated by a massive flood, there won’t be any alternate system to redirect processes to.
This can be avoided if your cloud provider runs multiple data centers. That way, you can configure redundant instances across multiple datacenters. In AWS for example, cloud computing resources are hosted in multiple locations around the world in what they call Regions and Availability Zones (AZ).
So if you have instances in the Northern Virginia (US-EAST-1) Region and that region goes down (like what happened in the recent AWS outage) but you also have instances in other regions, your business would still continue to operate.
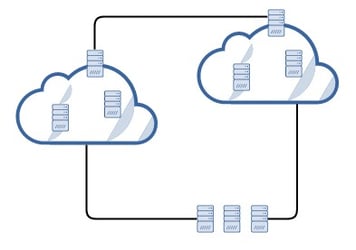
Other organizations take it a step further and deploy their systems using a multi-cloud architecture or a hybrid cloud architecture. Multi-cloud typically means subscribing with different cloud providers (e.g. Amazon, Azure, and Google), while hybrid cloud typically means deploying systems in public cloud and private (on-premise) infrastructures.
Share the workload
Having a backup failover system can help you quickly recover from an outage. But why wait for an outage if you can prevent one from happening? One of the reasons why systems go down is because they get overloaded.
To minimize the risk of an outage due to overloading, you can distribute the workload across multiple redundant systems in what is known as an active-active high availability (HA) cluster. You can do this by putting redundant systems behind a load balancer, which is the device responsible for distributing the workload. In AWS, workload distribution is achieved through what Amazon calls Elastic Load Balancing.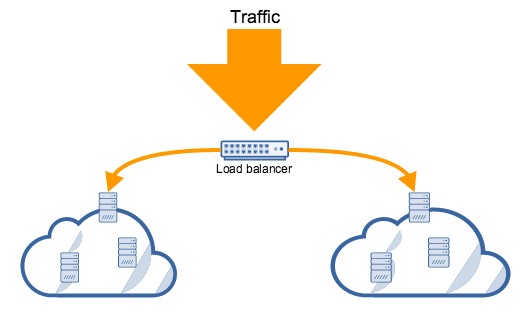
Make a disaster recovery plan
Taking into consideration budgetary constraints, no amount of redundancy and load balancing can make you totally immune to an outage. Just ask Amazon, owner of what is arguably the most resilient, fault tolerant cloud infrastructure in the world. And because an outage can happen, you need to prepare for it.
That’s where a disaster recovery (DR) plan comes in. A disaster recovery plan will help you know exactly what to do to bring you systems back into operation. A DR plan involves things like assessing risks, taking an inventory of assets, conducting business impact analysis, setting recovery point and time objectives, making backups and snapshots, planning out a DR strategy, and so on. We won’t go into the details here.
Once you have a DR plan, make sure you test it. Test it frequently. You should conduct walkthroughs, simulations, parallels, and even full interruption tests to make sure your DR plan actually works. One of the advantages about running things in the cloud is that it makes DR plan testing relatively easy.
Conclusion
Just because a cloud provider as big as Amazon can suffer an outage doesn’t mean you should start avoiding the cloud entirely. The economic and operational benefits of moving to the cloud far outweigh the risk of encountering outages like this. Besides, the chances of you suffering a much longer outage on an on-premise data center is much greater.



Comments